多模态推荐系统综述笔记
简介
- Tittle: A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions
- Author: HONGYUZHOU, XIN ZHOU, ZHIWEI ZENG, LINGZI ZHANG, ZHIQI SHEN
- Time: Feb 2023
- Journal: CoRR
Introduction
- 推荐系统解决: 信息过载.
- 推荐系统分为协同过滤 (针对的是用户行为)、基于内容过滤以及混合推荐.
不足:需要大量ui交互, 否则会影响推荐准确性. 因此引入多模态信息缓解数据稀疏问题和冷启动问题.
- 多模态模型可以挖掘多模态之间互补的信息 (这是单模态与隐式交互信息无法捕获的).
- 多模态信息可以用于补充历史交互 (这个补充是指模型可以不仅仅依赖ui交互吗? 还是说可以从中提取出潜在的交互信息?).
- 多模态数据还能反应用户在不同模态上的偏好 (说白了就是更加个性化).
- 不同物品的特定模态能反应他们之间的相似性和语义 (怎么理解?).
当前方法如何做的呢? 从不同模态中提取特征, 再进行模态融合, 将结果作为side information或者物品的表示 (一般用户是没有多模态信息的). VBPR作为第一个把视觉特征引入推荐系统的模型, 把视觉嵌入与id嵌入concatenate之后作为物品表示. 还有一些方法用GCN生成每个模态的表示再融合. 此外, 也有方法把知识图谱作为一个模态引入推荐.
MMRS的流程
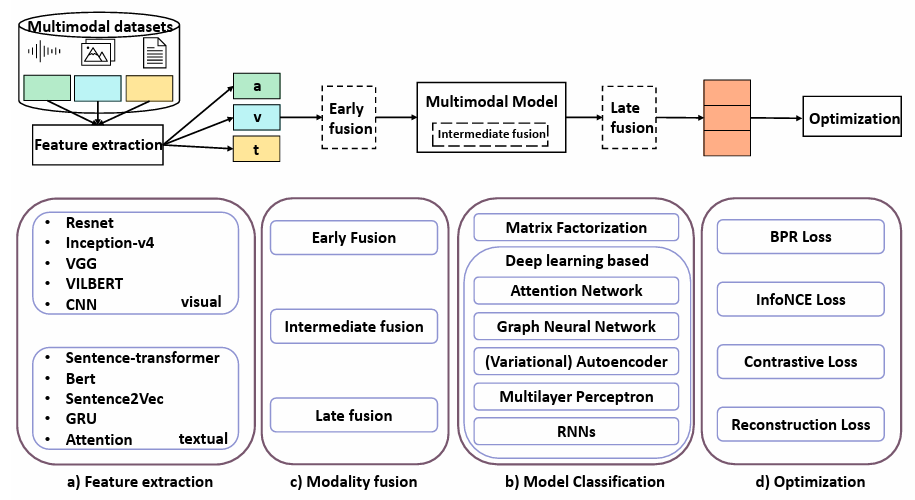
特征提取
数据集可能没有预先提取好特征, 这种情况下就需要自己进行特征提取.
- 特征提取的目的: 以低维且可解释的方法, 用嵌入来描述模态特征.
- 有两种方式:
- 使用预训练的模型进行特征提取, 然后将提取好的特征作为输入喂给推荐系统.
- 将特征提取的模型融入推荐系统, 进行端到端的训练. (也就是说, 这种情况下推荐系统的输入不是提取好的特征, 而是原始的图片)
- 一般来说, 不同模态的特征使用的提取方法是不同的. (比如图片用CNN, ResNet; 文本用GRU, BERT, Word2Vec等等)
模型分类 (按照模型方法)
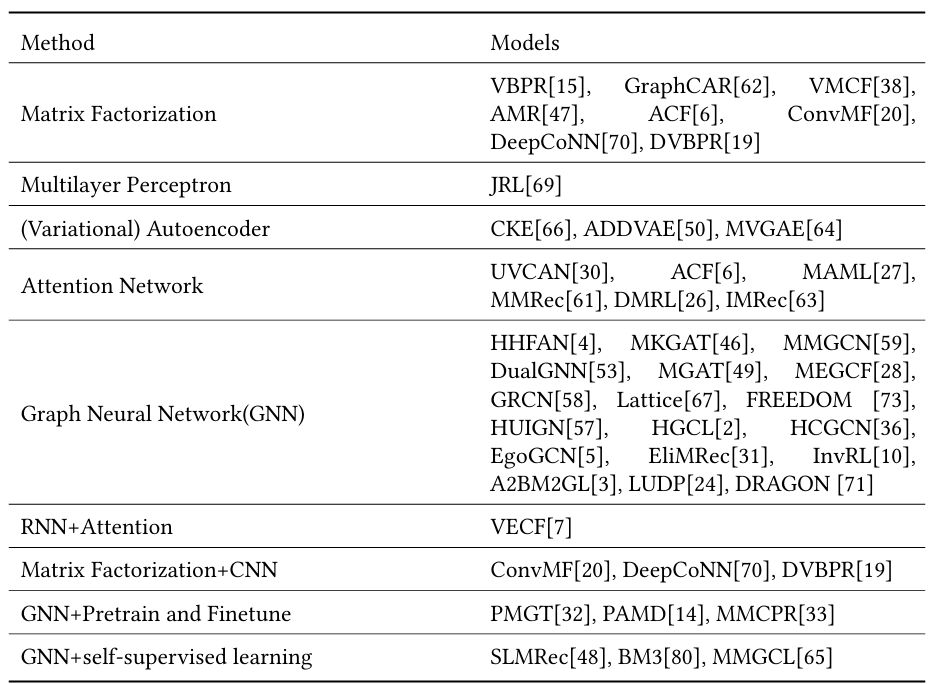
最早是基于矩阵分解 (MF) 和MLP的方法, 直接将多模态特征与id嵌入拼接作为物品表示. 随后各类技术被引入MMRS. 表1中的模型可能出现了多次, 因为用了不止一种方法.
MF
在之前评论评分已经被当作辅助信息帮助推荐了. (怎么用的? 需要去了解一下)
- VBPR 之前说了.
- AMR 指出了VBPR的脆弱性, 并采用了对抗学习.
- VMCF 使用节点表示产品, 用关系"also-viewed"构建了一个ii图, 与VBPR不同的是, 他所使用的损失函数不是BPR而是MSE. (这不就是ii共现图吗? 应该是第一个MMRS里考虑ii共现图的)
- ConvMF 将概率矩阵分解和CNN集成来捕获文档信息. (?)
- DVBPR 也是把CNN集成到MF中, 共同训练图像表示和推荐系统. (意思应该是端到端) 此外他还训练了对抗网络来生成和训练集中图像相似的新物品.
- GraphCAR 先将ui交互矩阵和user属性矩阵或item特征矩阵相乘, 然后使用两层GCN生成ui的潜在表示, 再内积和非线性变换. (在表中应该也属于GNN一类吧)
Deep Learning
MLP
不同的多模态特征可以体现用户偏好的不同方面.
- JRL把不同来源的信息使用MLP映射到统一空间, 通过学习来将多模态特征转化为ui嵌入. (后面的很多方法也都这样处理) 使用特征重建损失, 学习相关的ui表示. (什么意思? 自己构建了一个损失函数?)
CNN
大多数基于CNN的推荐模型利用其提取特征, 或捕获全局和局部特征来学习表示.
- ConvMF (MF) 用CNN捕获图像与文本的局部特征, 并和概率矩阵分解结合, 从而突破词袋模型的难以完全捕获文档信息的固有局限.
- DeepCoNN 使用预训练的词嵌入提取文本的表示 (文中说是用户和物品的语义表示, 难道数据集有专门用户的吗? 还是说使用共同的?), 分别给两个并行的CNN学ui表示, 后面的说的有点含糊不清, 等之后看看.
- DVBPR 利用孪生CNN框架, CNN最后一层用作物品表示. 端到端训练.
注意力网络
- 传统CF并没有专为MM设计, 比如ACF设计了物品级和组件级注意力模块, 但用户偏好使用的是固定的特征向量.
- MAML 建模了用户对不同物品的的不同偏好. 多模态信息拼接后输入到多层神经网络中, 还引入了注意力神经网络来识别不同偏好.
- DMRL 也考虑了多模态偏好, 他先利用解耦表示方法学习模态的独立因素表示, 基于此设计了一个权重共享的多模态注意力机制.
- DMR 也学习解耦表示,捕获模态间互补和共同的信息.
上述微视频推荐只考虑了用户的多模态偏好而忽视了物品的多模态信息.
- UVCAN 利用物品和微视频之间的共同注意力机制来更好地联合执行注意力, 使用堆叠注意力网络来处理用户资料和微视频多模态特征. 将多模态特征输入, 经过多步推理得到视频注意力. 学习完视频表示后再作为输入获得用户的注意力.
而对于新闻推荐, 大多都忽略了视觉信息.
- MM-Rec 先进行目标检测, 提取感兴趣的区域 (ROI), 然后用视觉语言模型来编码文本和ROI, 并使用共同注意力变换器来学习内在的跨模态关系. 此外引入了跨模态候选感知注意力网络, 学习点击新闻和候选新闻之间的关系.
- IMRec 基于用户在搜索新闻时更关注视觉印象, 开发了局部印象建模模块. (反正应该就是局部和全局的注意力)
RNN
- VECF 利用VGG模型获得预先分割的图像区域, 然后利用区域上的注意力来捕获用户偏好. 将评论信息视作弱监督信号, 使用Vanilla LSTM将注意力图像嵌入infuse到词生成中.
自编码器
CF总是受到交互信息稀疏的影响, 现有方法主要都是使用丰富的辅助信息来改进.
- CKE 收集知识库的异构信息, 使用Bayesian TransR来提取结构知识嵌入 (知识图谱吧), 贝叶斯堆叠降噪自动编码器来提取文本潜在表示, 贝叶斯堆叠卷积自动编码器来提取视觉方面的潜在表示. 最后提出了协同联合学习过程.
变分自编码器
变分自编码器把原始数据编码为隐空间中的分布, 在解码时是从该分布中采样一个点来进行解码
- ADDVAE 学习解耦表示来捕捉用户偏好, 通过最大化 互信息再将两个解耦的因子耦合, 再使用注意力机制将表示对齐.
- MVGAE 利用特定模态的变分编码器学习节点表示. 避免受到ui交互的稀疏性和特征噪声的影响.
GNN
主要思想是在传播过程中从邻居节点聚合信息并更新节点表示.
- PMGT 是利用融合的多模态特征和交互的预训练模型.
- MKGAT 创建多模态知识图谱来进行多模态推荐. (基于知识图谱的推荐利用重要的外部知识来提高性能. 然而,它们经常忽略多模态特征的不同数据类型)
- MMGCN 在ui图上对每个模态卷积. 但是平等地对待邻居信息聚合, 会受到冗余甚至噪音信息的影响.
- MGAT 在MMGCN的基础上添加了门控注意力机制, 记录复杂的用户交互模式.
- DualGNN 引入了偏好学习模块, 学习用户的多模态偏好. 此外对于模态缺失的影响还可以通过学习的多模态融合模式来改善.
- EgoGCN 构建了与MMGCN相同的特定模态的图, 但不限于在单模态图上传播信息. 多模态的传播结果与id嵌入拼接作为最后表示.
- EliMRec 指出利用因果推理和反事实分析可以消除单模态偏差.
- MEGCF 指出现有工作忽略了多模态特征提取(MFE)和用户兴趣建模(UIM)之间的不匹配. 他使用分离框架在MFE和UIM之间建立关联, 并在图卷积中加入了用户情感信息来加权.
上述基于GNN的微视频推荐方法只考虑用户和物品之间的关系, 而忽略了同质数据之间丰富的关系.(DualGNN也用了) 通过考虑每个模态的物品-物品关系构建了同质图; 或考虑用户共现频率构建图, 这有助于捕获同类节点之间的关系.
- LATTICE 利用物品模态信息构建了ii关系图, 还加入了注意力机制来融合多模态特征, 加入了自监督对比学习来最大化每个模态的物品嵌入与融合的多模态表示之间的一致性.
- DualGNN 考虑了用户共现图.
- DRAGON 利用了物品语义图和用户共现图. (前两者的缝合???)
- HUIGN 构建了两种不同类型的信息聚合方法和一个共同交互的物品图, 把用户意图传达给物品表示.
- LUDP 应该也算, 但是综述没有在这里提及.
从用户意图考虑:
- HGCL 指出大部分GNN技术是为同质图设计的, 但ui是异构数据.(其实我觉得当作同构没啥问题, u并不能说是用户嵌入, 而是用户偏好的嵌入, 向量空间上来看和物品嵌入同一空间也说得通)他用随机游走模型生成各自的同质图再用GNN技术.还使用了图对比框架.
- LATTICE 指出模态特征可以用于构建物品之间的潜在结构, 而不是仅仅用来融合到ui图中.
- FREEDOM 指出LATTICE学习潜在结构效率低下, 提前冻结ii图可以更好学习物品语义关系.他还基于度敏感边修剪技术对图进行去噪.
- HCGCN 与LATTICE不同的是, 额外引入了共聚类技术, 在同一子图中学习ui表示.
- A2BM2GL 也利用特征构建同质图.还学习了协同表示, 并利用注意力机制来学习短程长程节点重要性权重.
- LUDP 指出仅通过多模态特征丰富物品表示的模型学习用户偏好效果很差, 因此设计了ii模态相似度图和用户偏好图分别捕获潜在物品关系和用户模态偏好.
还有的GNN方法为每个节点采样子图, 根据模态对节点分组.
- HHFAN 构建了用户物品与多模态信息的异构图, 通过随机游走采样邻居.用FC层把节点全映射到同一向量空间, 并使用LSTM来聚合同一类型节点集的节点嵌入, 最后对不同类型节点使用自注意力和邻居感知注意力.
- HCGCN 对ui图进行子图采样并划分为组, 捕获用户行为模式.
- InvRL 采样子图学习不变掩码, 把多模态表示划分为不变和变异表示.(指出用表示关注语义意义而非影响用户偏好的因素的虚假相关问题.)
还有的方法使用多模态信息来细化图结构.
- GRCN 致力于识别和剪枝噪声边来细化ui图结构, 使用了邻居路由机制.最后用图卷积层和预测层.
- 综述把LATTICE这种利用多模态信息构建ii图的也算进来了, 那DRAGON和LUDP也算?
自监督学习
- SLMRec 把id嵌入视为具有视觉文本和听觉模态的特殊模态, 和MMGCN一样构建各个模态的图然后用GNN技术获得模态表示.他将各个模态视作单独的特征, 用自监督学习来产生物品不同视图, 学习潜在的训练信号.
- BM3 用自监督学习方法来克服计算成本和噪声监督信号问题.
- MMGCL 使用模态边丢弃和模态掩蔽、扰动负样本的一种模态使得正负样本之间只有一种模态差异, 通过这两个方法揭示模态之间的关系并确保每种模态都有贡献.
- 还有新的MMSSL, 指出多模态表示对标签有着强依赖性且在稀疏交互数据上鲁棒性很差.设计通过对抗扰动来进行数据增强的对比学习模型来学习交互与多模态信息之间的相互依赖关系.
预训练
预训练模型已被证明在自然语言和图像中很有用.图像和文本等辅助信息已被用于提高推荐系统的有效性.
- PMGT 考虑多模态特征和物品关系来学习物品表示.使用注意力机制按权重聚合多模态特征.它开发了一个小批量上下文邻居采样算法来采样负样本和正样本用于处理大规模图.完成预训练后可以获得节点表示, 并使用它们来初始化下游任务的物品嵌入.
- MMCPR 在同质图和异构图上预训练, 对于用户考虑评论文本以及uu图, 对于物品考虑文本图像和ii图.也使用了对比学习.
- PAMD 试图理解物品的共同和独特特征.使用解耦编码器将模态特征划分为共同和特定表示.然后对比学习执行跨模态对齐, 将模态共同表示与原始表示对齐.
- Amazon数据集提供的多模态数据也都是ResNet之类的模型提取过的, 应该也算是预训练?
模型分类(按模态融合方法)
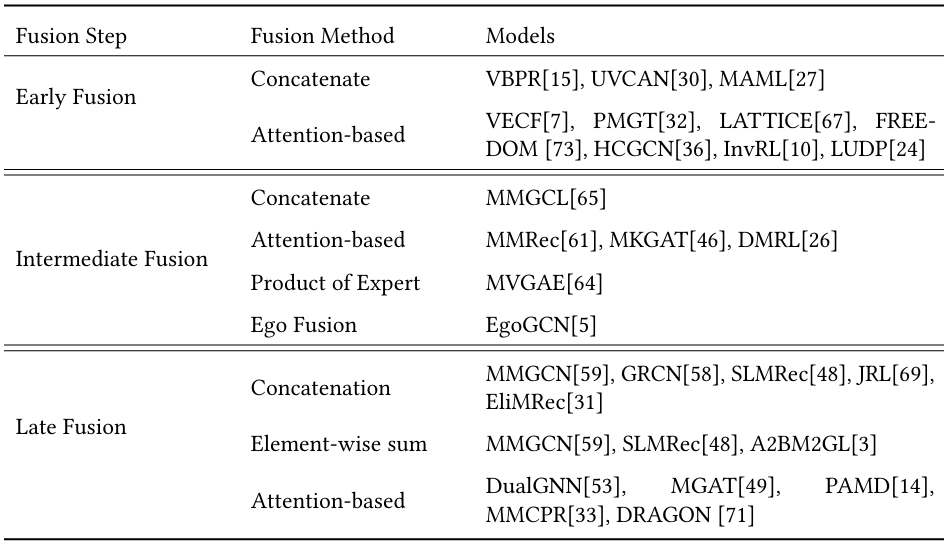
此外还存在一些模型设计了自己的模态融合方法.
- MVGAE 采用特定模块来区分具有多个不确定性水平的模态来解决拼接的问题.(??)
- IMRec 不进行模态融合, 把impression image作为整体进行编码.(??)
衡量与优化
评估指标
- accuracy
- precision
- recall 在实际情况下, 数据集中的正负样本是不平衡的. 通常, 正样本不到10%, 这意味着即使将所有物品预测为负例, 你也可以获得高于0.9的准确率. 我们的目标是衡量预测正例的能力.
- F1-score 结合了召回率和精确率的结果.
- hit rate 表示测试集中预测的前k列表中命中物品的比率. 如果用户实际与我们推荐的前k个物品之一进行交互, 则认为是命中.
- Normalized Discounted Cumulative Gain, NDCG
- Mean Average Precision, MAP
目标函数
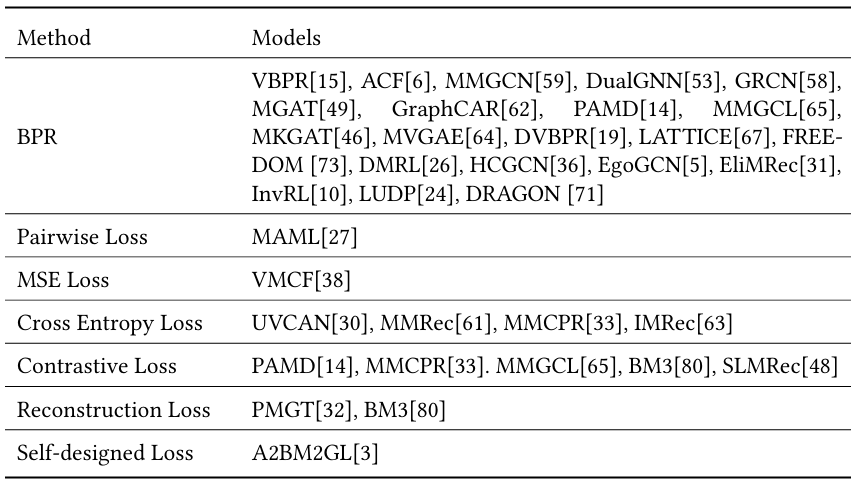
Reference
@article{DBLP:journals/corr/abs-2302-04473, |