多模态知识图谱综述笔记
简介
- Tittle: Multi-Modal Knowledge Graph Construction and Application: A Survey
- Author: Xiangru Zhu, Zhixu Li Member, IEEE, Xiaodan Wang, Xueyao Jiang, Penglei Sun, Xuwu Wang, Yanghua Xiao Member, IEEE, Nicholas Jing Yuan Member, IEEE
- Time: 11 Feb 2022
- Journal: IEEE Transactions on Knowledge and Data Engineering
22年多模态知识图谱综述。
主旨
背景
RDF
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。可以类比知识图谱的三元组。
Traditional KG
Traditional KG is defined as a directed graph \(\mathcal{G}=\{\mathcal{E,R,A,V,T_R,T_A}\}\).
- \(\mathcal{E}\): entities
- \(\mathcal{R}\): relations
- \(\mathcal{A}\): attributes
- \(\mathcal{V}\): literal attribute values
- \(\mathcal{T_R=E\times R\times E}\), \(\mathcal{T_A=E\times A\times V}\) are sets of relation triples and attribute triples respectively.
Two Ways for representing MMKG
MMKG (Multi-Modal Knowledge Graph,多模态知识图谱)
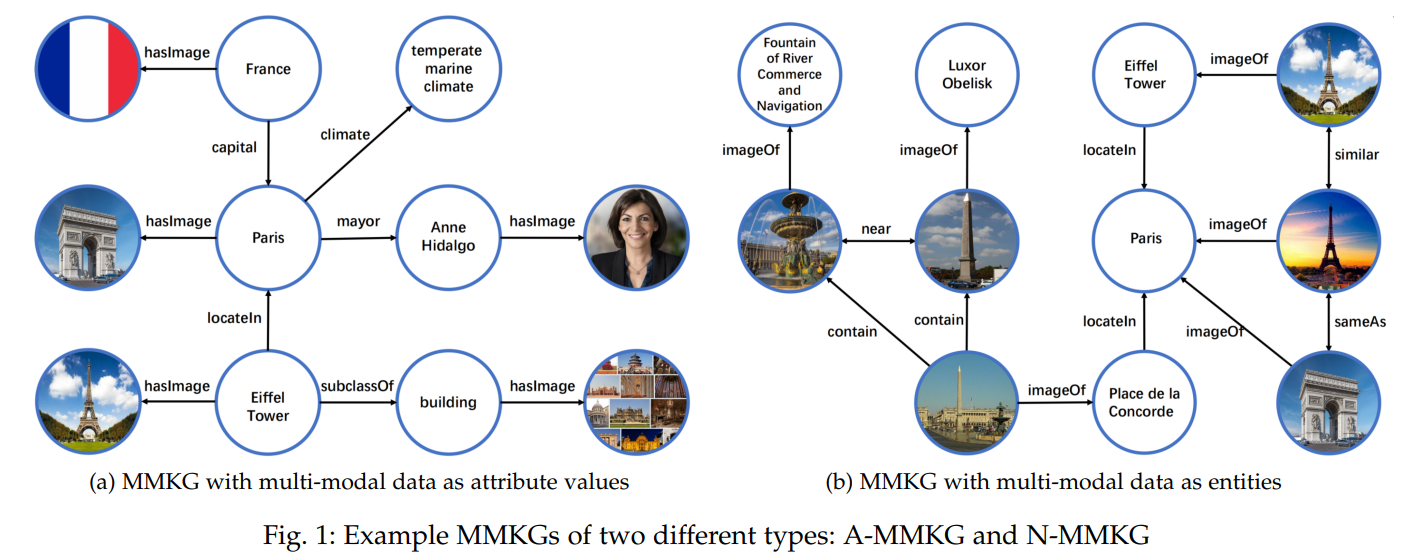
A-MMKG: Taking multi-model data as particular attribute values of entities or concepts, as shown in Fig.1(a).
Denote as \(\mathcal{G}=\{\mathcal{E,R,A,V,T_R,T_A}\}\) where \(\mathcal{T_A=E\times A\times (V_{KG}\cup V_{MM})}\) is the set of attribute triples,
\(\mathcal{V_{KG}}\) is the set of the KG’s attribute values and \(\mathcal{V_{MM}}\) is the set of multi-modal data.就是将原来的 \(\mathcal{T_A}\) 中的 \(V\) 并上多模态的数据。
N-MMKG: Taking multi-model data as entities in KGs as the example shown in Fig.1(b).
Denote as \(\mathcal{G}=\{\mathcal{E,R,A,V,T_R,T_A}\}\) where
\(\mathcal{T_R=(E_{KG}\cup E_{MM})\times R\times (E_{KG}\cup E_{MM})}\) is the set of relation triples,
\(\mathcal{E_{KG}}\) is the set of KG entities and \(\mathcal{E_{MM}}\) is the set of multi-modal data.将多模态数据拓展到实体集,当作实体考虑。
Two images can also be associated in one of the following relations:
- contain: One image entity visually contains another image entity by the relative position of images.
- nearBy: One image entity is visually nearby another image entity in an image.
- sameAs: Two different image entities refer to the same entity.
- similar: Two image entities are visually similar to each other.
In addition, in N-MMKGs an image is usually abstracted into a number of image descriptors, which are usually summarized into feature vectors of the image entity at pixel level, such as GHD (灰度直方图描述符, Gray Histogram Descriptor), HOG (定向梯度直方图, Histogram of Oriented Gradients Descriptor), CLD (颜色布局描述符, Color Layout Descriptor) and so on.简单来说,N-MMKG中的图像是经过某些方法处理过后的特征向量。
Examples of A-MMKG and N-MMKG illustrated in Table.1.

Multi-Modal Tasks
- Image Captioning. 图像描述. Image captioning aims at generating the descriptive caption for a given image.
- Visual Grounding. 视觉定位. Visual grounding aims at locating an object with designated description in a given image.
- Visual Question Answering (VQA). 视觉问答. VQA aims at generating a textual answer for a textual question with the help of a relevant image.
- Cross-Modal Retrieval. 跨模态检索. There are two classic cross-modal retrieval tasks including searching for images through a text, and searching for texts through an image.
Fundamental challenges of Multi-Modal Learning
Multi-modal Representation. The multi-modal representation uses the potential complementary of multi-modality to learn feature representation.
主要是两种方法,拼接和融合。拼接是将每种模态投射到各自的向量空间,如linear correlation,再通过一些别的方法来将各个模态进行交融。融合是将所有模态全部投射到一个统一的空间,如VGG、ResNet。potential complementary: 指模态的潜在互补,每种模态都有一些别的模态没有的信息,如文字“这有一个男孩”,在图片中可以看出男孩的肤色是黑色,那么实际上我们知道这是一个黑人男孩。
Multi-Model Translation. Multi-modal translation learns to translate from a source instance in one modality to a target instance in another.
The example-based translation models build bridges between different modality through dictionary,
while the generative translation models build a more flexible model which can transform one modal to another.Multi-Model Alignment. Multi-modal alignment aims to find the correspondences between different modalities.
It can either be directly applied in some multi-modal tasks such as visual grounding, or be taken as a pre-training task in multi-modal pretrained language models.Multi-modal Fusion. Multi-modal fusion refers to the process of joining information from different modalities to perform a prediction,
where various attention mechanism such as gated cross-modality attention, bottom up attention etc. are applied to model the interaction between different kinds of features in the cross-modal module.Multi-modal Co-Learning. Multi-modal co-learning aims to alleviate the low-resource problems in a certain modality by leveraging the resources of other modalities through the alignment between them.
多模态联合学习通过多模态对齐利用其他类型的模态来缓解某一low-resource的模块。
Multi-Modal Pretrained Language Model
Based on a large-scale unsupervised multi-modal data set with text-image pairs, 许多工作都在学习多模态预训练语言模型 with designed 预训练自监督任务, including masked language model, sentence image alignment, masked region label classification, masked region feature regression, masked object prediction, etc. 多模态预训练语言模型在下游任务中确实有效。
Can be divided into 1. single-stream models and 2. two-stream models, in terms of the Transformer-based fusion process of different modality.
单流模型 Single-stream models, such as VL-BERT, ViLT, input all modal information into a single Transformer encoder for fusion by self-attention modules.
双流模型 Two-stream models, such as LXMERT, input different modal information into their own encoders and fuse these representation from different modal encoder by an additional cross-attention module.
The final output representation not only contains the cross-modal interaction, but also preserves the interaction within each modality.
不仅包含了每个模块之间的交互,还保留了每个模块内部的交互。
MMKG benefit downstream tasks
- MMKG为实体与概念的表达补充足够丰富的background
knowledge,特别是那些long-tail ones 长尾问题。
long-tail: a few classes(a.k.a. head class) occupy most of the data, while most classes(a.k.a. tail class) have rarely few samples. 少数类(头类)占用大部分数据,而大多数类(尾类)只有少量的数据。 - MMKG可以提升模型对图像中隐藏的物体的理解能力。Unseen object pose great challenge for statistic based models. 这主要是利用符号知识提供的在视觉上不可见物体的符号信息,或在可见物体和不可见物体之间建立语义关系。
- MMKG支持多模态推理。Multi-modal reasoning.
- MMKG在一些NLP任务中,可以提供多模态数据作为附加特征来帮助弥合信息鸿沟。Take entity recognition for example, an image could provide sufficient infomation to identify whether "Rocky" is the name of a dog or a person.
MMKG Construction. MMKG的构建
MMKG构建的实质是将KG中的符号知识(实体、概念、关系等)与他们对应的图像相关联。有两种相反的方式来完成:1. From images to symbols: Labeling images; 2. From symbols to images: Symbol grounding.
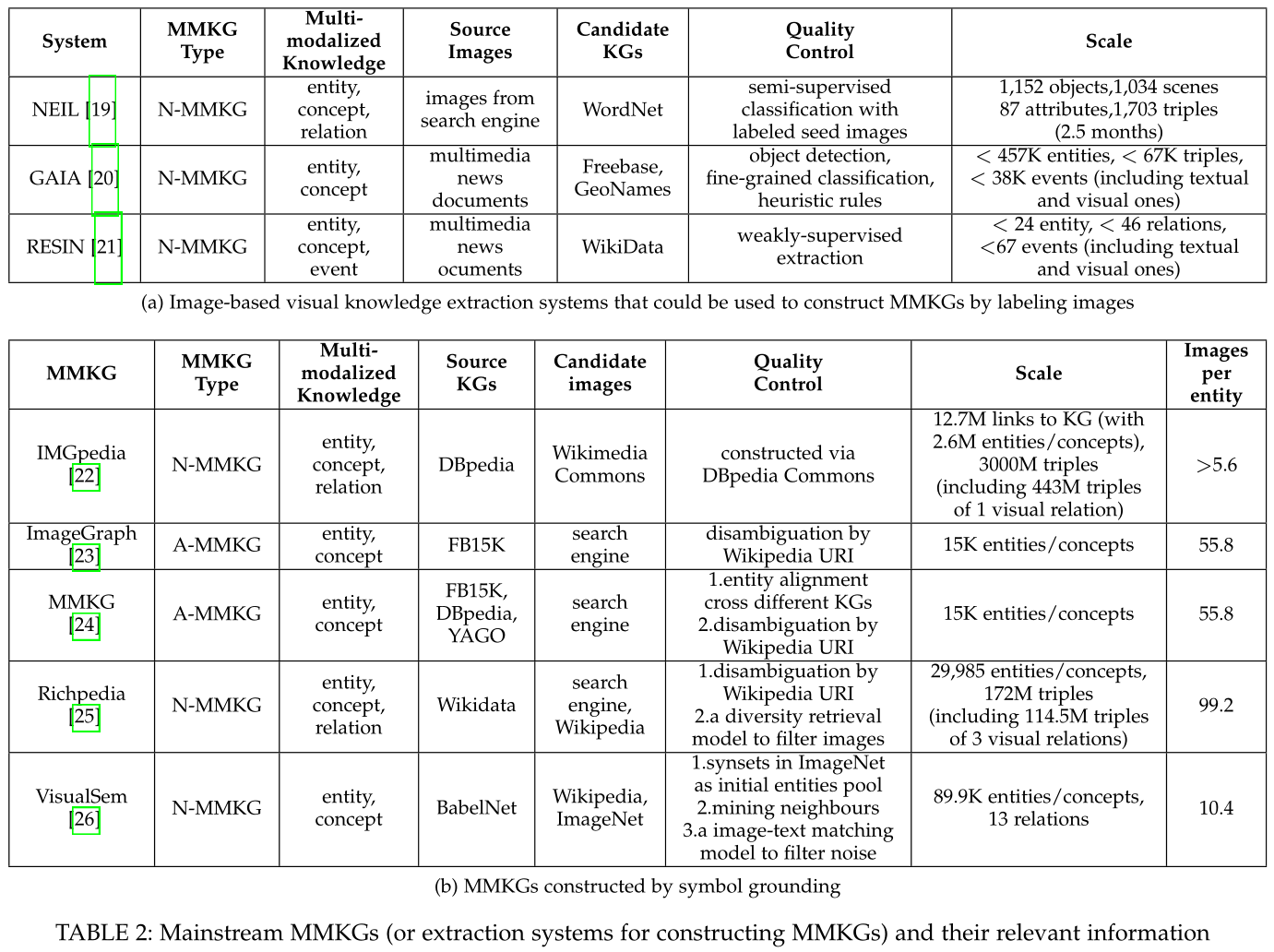
From Images to Symbols: Labeling Images
The CV community has developed many image labeling
solutions, which could be leveraged in labeling images with
knowledge symbols in KG. Most image labeling solutions learn the
mapping from image content to a wide varity of label
sets (including objects, sences, entities, attributes, relations, events
and other symbols).
The learning procedure is supervised by a human
annotated data set, seen Fig.2.
Table.2(a) lists some well-known image-based visual knowledge extraction systems constructed. 这些系统可以通过图像标注来构建MMKG。 According to the category of symbols to be linked, the process of linking images to symbols could be divided into several fractionized tasks:
- visual entity/concept extraction: Aim to detect and locate target visual objects in images, and then label these objects with entity/concept symbols in KGs. 从图像中识别实体并用KG中的entity标记;
- visual relation extracion: Aim at identifying semantic relations among detected visual entities/concepts in images, and then labeling them with the relations in KGs. 识别已识别的实体之间的语义关系并用KG中的relation标记;
- visual event extraction: Aim at 1) predicting the
visual event types and 2) locating and exacting objects in source images
or videos as visual arguments.
预测视觉事件类型,定位并提取对象作为可视参数。
- EVENT: dynamic interaction among arguments, including a trigger and several arguments with their corresponding argument roles.
- Trigger: a verb or a noun indicating the occurrence of an event.
- Argument role: the semantic relation between an event and an argument such as Time, Person, Place.
如“我在十点半睡觉”是一个event,睡觉是trigger,argument是十点半,argument role是Time,另外我也可以是argument,这时argument role就是Person。
Visual Entity/Concept Extraction 视觉实体/概念提取
Challanges
The main challenge with this task lies on how to learn an effective
fine-grained extraction model without a large-scale, fine-grained,
well-annotated concept and entity image dataset.
CV中虽然有丰富的标注良好的图像数据,但这些数据集几乎都是粗粒度coarse-grained的概念图像,无法满足MMKG构建对细粒度概念和实体图像标注数据的要求。
CV图像分类中的细粒度/粗粒度(fine-grained/coarse-grained): 粗粒度指类别之间差异大,如人、汽车、树;细粒度指类别之间差异小,如200种鸟的分类、100种花的分类。
由于细粒度类别属于同一个大类,所以各类别之间的差距很小,这些细微的差距容易被光照、颜色、背景、形状和位置等变化因素覆盖,导致细粒度图像分类相对困难。
Progresses
Existing efforts could be roughly divided into two categories:
- object recognition methods, which label a visual entity/concept by
classifying the region of a detected object; and
- visual grounding methods, which label a visual entity/concept by mapping a word or phrase in a caption to the most relevant region.
对象识别方法对检测到对象的区域进行分类,来标记视觉实体/概念;视觉定位是将标题中的单词或短语映射到图像中最相关的区域。这两个的侧重点分别是从图像区域到实体,一个是从实体到图像区域。
Object Recognition methods
早期工作中,提供的图片基本都只有一个物体,但现实生活中的图像往往十分复杂,以至于无法用仅仅一个label来表示。为了识别多个视觉实体,我们需要预训练的检测器和分类器来标注视觉实体(以及属性及场景)及其在图像中的位置。
检测器的训练数据都是有监督数据,主要来自public image-text datasets(such
as MSCOCO, Flickr30k, Flick30k
Entities and OpenImages)或预标注的种子图像
pre-labeled seed images.
在检测过程中,检测器捕获一组可能对象的候选区域region proposals,并挑出实际包含对象的候选。在检测到的区域中,预先训练的分类器识别具有entity-level(例如BMW 320)或concept-level(例如Car)标签的候选视觉对象。
被识别出来的实体一般不会直接被认为是visual
entities,这是因为一般会有大量重复的实例 at different view points,
positions, poses and appearances. 因此我们一般会选择最具有代表性的
visual object 作为 visual entitiy。
最常用的方法是对选出来的图像区域进行聚类,每个聚类的中心就被认为是一个新的
visual entity。
缺点:当该方案需要生成大量labels时,需要很多的预处理工作,比如预训练的规则、预确定的实体列表、预训练的细粒度检测器和分类器等,这会导致该方案的鲁棒性scalability下降。
Visual Grounding Method
视觉实体提取问题简化为开域视觉定位问题,即定位标题中的每个短语对应的图像区域,从而获得图像中的视觉对象及其标签。
一般在visual entity extraction中,训练用的 labeled data 需要 with bounding boxes and pre-defined schema with a fixed set of concept, which is difficult to be used for large-scale visual knowledge acquisition.
幸运的是,Web上有很多image-captions pairs,来为visual knowledge extraction提供弱监督weakly supervise without relying on the labeled bounding boxes.
As illustrated in Fig.3 below, weakly supervised learning mainly includs three classical categories:
- 不完全监督 Incomplete supervision:
训练数据中只有一部分数据被给了标签,有一些数据是没有标签的。
- 不确切监督 Inexact supervision:
训练数据只给出了粗粒度标签。
- 不精确监督 Inaccurate supervision: 给出的标签不总是正确的。
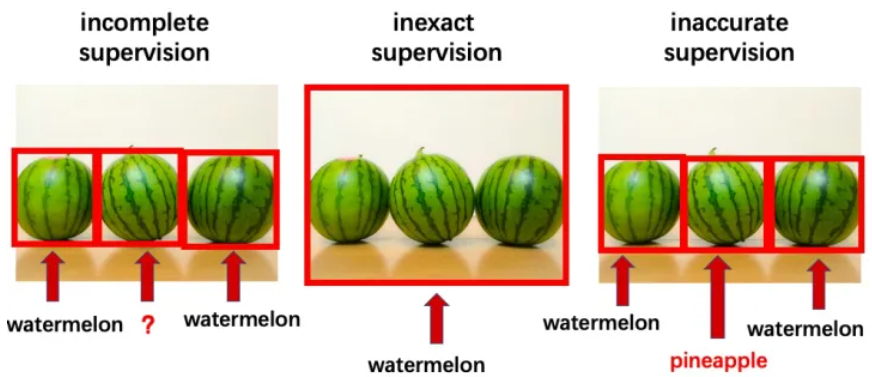 在实际操作中,这三类经常同时发生。
在实际操作中,这三类经常同时发生。
关于弱监督学习可以参考周志华 《A Brief Introduction to Weakly Supervised Learning》(2018.1)
当从弱监督的图像标题对重提取信息时,通常根据空间热力图(shown as Fig.4)直接选择给定单词的活动像素作为视觉对象的区域。

在同一语义空间中的文本、图像表示,每个短语的热图可以通过基于注意力的方法和基于显著性的方法作为跨模态权重来学习,shown as Fig.5。
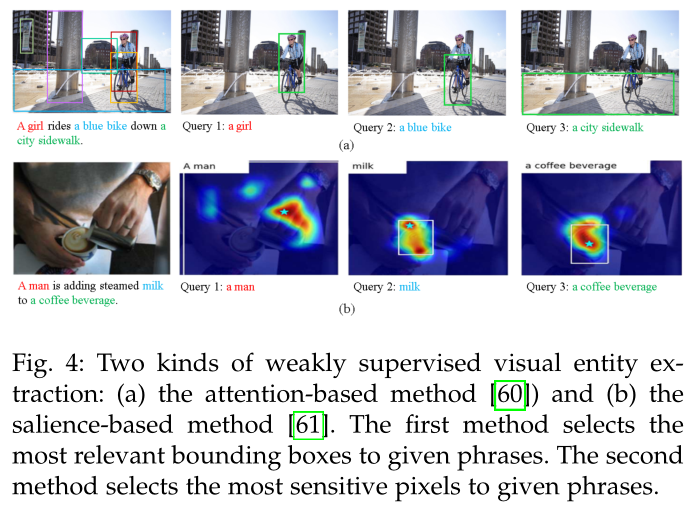
- 在训练时,基于显著性的方法通过梯度计算,直接将像素对给定短语的敏感度视为热力图的值。
- 基于注意力的方法将跨模态相关性视为热力图的值,与基于显著性的方法相比,其更受欢迎。
有的热图是根据标题中提到的每个实体的图像区域之间的相似性生成的, 而有的热图是根据图像区域与可能的事件参数角色类型之间的相似性生成的。
在测试时,对热图进行阈值设置,以获得可视对象的合适包围框。如果kg中已有视觉实体/概念的边界框与新的边界框没有重叠,则将该边界框创建为新的视觉实体或概念。
尽管视觉定位方法不依赖于带有边界框的标记数据,但实际上仍需要人工验证。 一些工作试图在训练阶段增加对常识、关系和事件参数的约束,以增加监督信息。 在与MMKG的构建相关的工作中,视觉定位的精确度低于 70%。
通过视觉定位的视觉对象可以是实体(例如 Barack Hussein Obama)、概念(例如地点、汽车、石头)、属性(例如红色、短)。然而,图像和文本的语义尺度不一致可能导致不正确的匹配。例如,troops可能会映射到several individuals wearing military uniforms,而Ukraine (country)可能会映射到Ukrainian flag,这两者都是相关的但并不等同。
Opportunities
随着多模态预训练语言模型的出现,多模态预训练语言模型强大的表示能力增强了提取实体和概念的能力。 图像块和单词的映射可以直接在模型的自注意力图中可视化,而无需额外的训练。 ViLT 的预测示例如图 6 所示。多模态预训练语言模型如 CLIP,在数亿网络规模的图像-文本数据上进行了预训练,在著名人物和地标建筑上具有很高的准确性,这将在构建一个MMKG人物或建筑时减少大量的数据收集和模型训练工作量。一些预训练的视觉转换器模型已经具有很强的视觉对象分割能力,即使在高度模糊的情况下也能聚焦于前景对象,例如 DINO ,这将提高定位视觉对象和对齐跨模态知识的性能。

Visual Relation Extraction 视觉关系提取
Challanges
虽然视觉关系检测在CV社区已经得到了广泛的研究,但大多数检测到的关系都是视觉对象之间的表面视觉关系,如(person, standing on, beach)。不同的是,为了构建MMKG,视觉关系提取任务旨在识别在kg中定义的更一般的语义关系类型,如(Jack, spouse, Rose)。
Progresses
现有的工作大致可分为基于规则的关系抽取和基于统计的关系抽取,其余的一些工作主要集中在长尾关系和细粒度关系上。
Rule-based Relation Extration
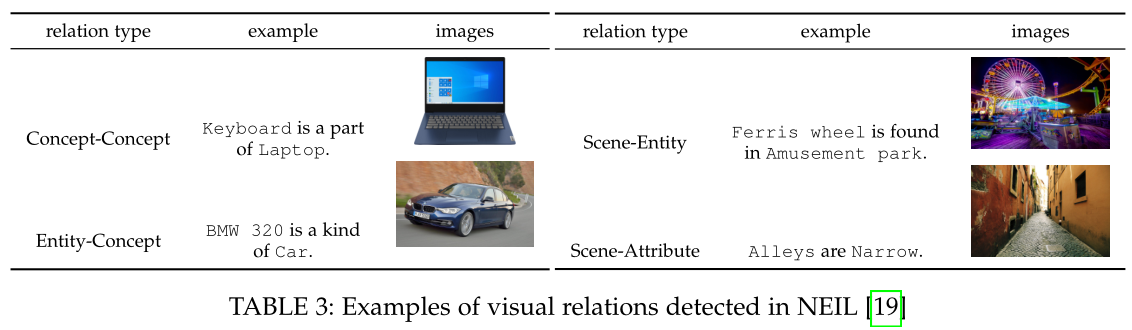
传统的基于规则的方法主要关注一些特定类型的关系,如空间关系和动作关系。这些规则通常由专家预先定义,判别特征通过启发式方法进行评分和选择。
在基于规则的方法中,要检测的关系是根据标签的类型和区域的相对位置来定义的。例如,如果一个对象的边界框总是在另一个对象的边界框内,则它们之间可能存在 PartOf 关系。表 3 列出了在NEIL中检测到的几种视觉关系。提取过程中,检测到的一对对象之间的关系反过来又会对新实例标记的附加约束。例如,“Wheel is a part of Car”表示 Wheel 更有可能出现在 Car 的边界框中。基于规则的方法提供高度准确的视觉关系,但它们依赖于大量的手动工作。所以在大规模MMKG建设中是不实用的。
Statistic-based General Relation Extration
基于统计的方法将检测到的对象的视觉特征、空间特征和统计等特征编码为分布式向量,并通过分类模型预测给定对象之间的关系。与基于规则的方法相比,基于统计的方法能够检测到训练集中出现的所有关系。
一些工作证明谓词在很大程度上依赖于主客体的类别,但主客体不依赖于谓词,主客体之间也没有依赖关系。 例如,在三元组(人、骑、大象)中,人和大象表示关系可能是骑而不是穿。因此,为了利用依赖关系,一些工作通过对象的标签将语言模型的语言先验添加到统计模型中,设置了一个更严格的约束,即三元组的隐藏层表示应满足主语 + 谓词 \(\approx\) 宾语。令人尴尬的是,语言模型带来很大的改进,但视觉信息的贡献却很小。
图像中检测到的对象和关系可以表示为图。图结构使边能够从其他节点和边中获得更多消息,从而以更高的精度对关系进行分类。例如,对象和关系可以表示为两个互补的子图,其中节点根据周围边的值迭代更新,反之亦然。 一些工作使用注意力图卷积神经网络来学习上下文对象和边。
Long-tail and Fine-grained Relation Extraction
尽管基于统计的方法能够检测一般关系,但很难检测长尾关系。原因是具有大量样本的有偏差的数据集使得预测关系更加困难。为了消除训练集中不平衡样本的影响,为了消除训练集中不平衡样本的影响,学者提出了一种新的无偏度量(Mean Recall@K)来平均所有类型关系的召回率,而不是所有样本的召回率,避免忽略只有少量样本的关系。还有很多其他的工作,主要是通过迁移学习、少镜头学习和对比学习来检测少量样本的关系,但仍然局限于隐层的特征融合。
细粒度关系是一种长尾关系。现有的从特征融合角度对长尾关系问题的研究未能很好地区分细粒度的关系。例如,例如,模型倾向于预测“on”而不是细粒度的关系“sit on”/"walk on"/"lay on"。
检测更复杂和细粒度的关系更困难,例如人与对象交互和动作检测。因为一个人的姿势是由身体的许多组成部分决定的。例如,(person, play, violin) 和 (person, hold, violin) 的图像之间存在细微差别。在早期研究中,动作被定义为身体不同部位的一系列姿态,并通过启发式方法挖掘识别特征。在目前基于统计量的检测中,判别特征采用更严格的对比损失函数滤波,但显然仍过于粗糙。
Opportunitiies
尽管现有的工作很多,但仍有许多具有挑战性的问题没有解决。例如:
视觉知识关系判断 许多从图像中提取的视觉三元组只描述了图像的场景,由于它们不是被广泛接受的事实,因此不能被视为视觉知识。难点在于我们如何从场景信息的三元组中识别视觉知识的三元组。
基于推理的关系检测 现有的关系检测方法通过融合视觉特征和语言先验的隐藏统一表示来预测关系。例如,如果一个图像中有一个人和一个足球,并且(head, look at, sth) (arm, swing, -) (foot, kick, sth) 同时满足,则该动作将被判断为(person, kick, football)。不幸的是,这个数据集是手动构建的。我们需要自动总结关系检测的推理链。
Visual Event Extraction 视觉事件提取
视觉事件提取可以分为两个子任务:
- 预测视觉事件类型;以及
- 定位和提取源图像或视频中的对象作为可视参数
Challenges
该任务面临以下几个挑战:
- 视觉事件提取需要对不同的事件类型预先定义模式,但大量的视觉事件还没有被专家定义。如何将视觉模式自动挖掘为事件模式?
- 如何从图像或视频中提取视觉事件的视觉论据?
Progresses
当前工作主要focuses on两个方面: 1) 视觉事件模式挖掘,将最相关的视觉实体(或概念)检测并标记为新模式; 2) 视觉事件参数提取,根据事件模式从视觉数据中提取参数角色区域。
Visual Event Schema Mining
例如,事件 Clipping 具有诸如 Agent、Source、Tool、Item、Place 等参数角色,并且在剪羊毛的图像中它们分别是 Man、Sheep、Shears、Wool、Field。该任务主要旨在识别视觉事件,而不是定位和提取其视觉参数。
然而,在大规模的可视化事件提取中(如新闻),许多事件的视觉图式还没有被手动定义,这需要大量专家的工作。
来自Internet的大量图像标题对使得挖掘和标记事件模式的视觉模式成为可能。因此,此任务简化为从给定事件的图像中查找指示正确事件类型的视觉模式的频繁项集。可以从带有事件触发器的图像标题对中检索事件的图像集合作为查询。通过视觉定位的方法,将候选图像补丁用文字或短语标注在字幕中。可以利用启发式方法(如Apriori算法)挖掘频繁的视觉图像补丁,找到关联规则,通过视觉模式预测事件类型。
Visual Event Arguments Extraction
视觉事件参数提取实际上是提取一组具有关系约束的视觉对象的任务。视觉参数可以通过完全监督方法(如对象识别)或弱监督方法(如视觉基础)进行标记。根据视觉事件提取的两个子任务,根据事件图像的全局特征对事件类型进行分类,并将事件参数提取为对事件类型最敏感的局部区域。
但是,在弱监督方法中,我们不能确定所提取的视觉对象之间的关系是否与文本中的关系一致。因此,视觉参数和文本参数的关系也应该分别对齐。有的工作将从一个事件的图像中提取的情景图与抽象意义表示图(AMR图)对齐,AMR图根据跨模态参数的语义和类别表示该事件标题的语义结构。联合提取中还增加了语义、事件类型、事件参数角色、视觉信息和文本信息一致性等诸多约束条件。
与图像相比,视频更适合于事件提取,因为一个事件的时间包围框可能跨越整个视频,所有的参数可能不会在一帧中显示。为了简化任务,可以从只包含一个事件的短视频片段中提取了三个关键帧的参数,这些关键帧是与视频标题最匹配的帧。
Opportunities
这一课题的研究还处于早期阶段,还有很多问题值得探索。例如:
- 从包含多个事件的长视频中提取连续事件的问题还没有解决。
- 多子事件视频事件提取。例如,将“煮咖啡”事件分为清洁咖啡机→倒入咖啡豆→打开咖啡机等一系列步骤,每一步也可以视为一个事件。顺序步骤需要按照步骤的时间轴进行提取和列出,这是目前方法难以解决的问题。
From Symbols to Images: Symbol Grounding
符号定位是指寻找合适的多模态数据项(如图像)来表示传统KG中存在符号知识的过程。与图像标注方式相比,符号接地方式在MMKG施工中应用更为广泛。大多数现有的MMKG都是这样构造的。
We cover the process of grounding symbols to images in several fractionized tasks: Entity Grounding, Concept Grounding, Relation Grounding.
Entity Grounding
实体定位旨在将知识图谱中的文本实体定位到其相应的多模态数据,例如图像、视频和音频。
Challenges
- 如何以低成本为实体找到足够多的高质量图像?
- 如何从大量噪声中选择最匹配实体的图像?
Progresses
From Online Encyclopedia (such as Wikipedia)
在维基百科中,一篇文章通常用图像和其他多模态数据来描述一个实体。 Wikipedia 和 DBpedia 提供了许多工具(例如 Wikimedia Commons )来帮助在 DBpedia 中的实体与 Wikipedia 中的相应图像或其他模态数据之间建立连接。研究人员很容易使用像维基百科这样的在线百科全书来构建大规模 MMKG 的第一个版本。
然而,基于百科全书的方法有三个主要缺点:
- 首先,每个实体的图像数量是有限的。维基百科中每个实体的平均图像数量为 1.16。
- 其次,维基百科中的许多实体图像仅与其对应的实体相关,而不是与实体完全相关。例如,维基百科中北京动物园的图片中存在动物、建筑、牌匾、雕刻等多张图片,很容易导致语义漂移。
- 最后,基于维基百科构建的MMKG的覆盖范围仍有待提高。英文维基百科有600万个实体(文章),这是从英文维基百科收获的MMKG容量的上限。根据我们的调查,近 80%的英文维基百科文章没有对应的图像,其中只有 8.6 %有超过 2 个图像。
From The Internet Through Web Search Engines
为了提高 MMKG 的覆盖率,提出了基于搜索引擎的解决方案。通过查询实体名称从搜索引擎的搜索结果中找到图像。一般来说,排名靠前的结果图像很有可能是要搜索的实体的正确图像。然而,基于搜索引擎的方法很容易将错误的事实引入 MMKG。众所周知,搜索引擎结果可能是嘈杂的。另一个原因是指定搜索关键字并非易事。例如,搜索查询“Bank”不足以找到 Commercial Bank 的图像,因为它也产生了 River Bank 的图像。因此,已经有很多清理候选图像的工作。通常通过添加父同义词集或实体类型来扩展查询词以消除歧义。在为实体选择最佳图像时,多样性也是不可忽视的问题。训练图像多样性检索模型以去除冗余的相似图像,使图像尽可能多样化。
由于在构建过程中实体及其视觉特征的解耦,基于实体接地的MMKG具有区分视觉相似实体的能力,如图7所示。实体定位方法使得构建面向领域的细粒度MMKG成为可能。

与基于百科全书的方法相比,基于搜索引擎的方法覆盖面更好,但质量更差,因此这两种方法经常一起使用。例如,可以通过从搜索引擎为每个实体收集更多图像或将每个图像映射到它包含的所有实体以扩大实体图像的数量来提高从维基百科获取的 MMKG 的覆盖范围。
Opportunities
这个方向还有很多未解决的问题。
- 实体被定位成几个图像,每个图像只是实体的一个方面。例如,一个人的图像集合可以是不同年龄的图像、生活照片、事件照片、单人照片和家庭照片。如何确定最典型的图像?图8以特朗普为例。

- 现实世界的实体是多角度的,在不同的上下文中将一个实体与多个图像相关联是合理的。这促使我们提出一项新的多定位任务,该任务从给定特定上下文的实体中选择最相关的图像。例如,美国第 45 任和现任总统唐纳德·特朗普 (Donald Trump) 拥有许多可以从网络上收集的不同图像。但如图 8 所示,任何单个图像都不适用于所有不同的上下文。然而,将实体的不同方面映射到不同上下文中最相关的图像并非易事。首先,实体的图像池很难建立,因为图像池的完整性无法保证,在某些上下文中很容易漏掉一些相关的图像。其次,为特定上下文的实体消歧图像具有挑战性,因为上下文通常是嘈杂的并且包含稀疏信息,并且需要更多的背景信息来指导语义信息的获取。最后,作为一项新任务,标记数据的缺乏是一个大问题。
Concept Grounding
概念定位旨在为视觉概念找到具有代表性的、有区别的和多样化的图像。
Challenges
虽然一些视觉上统一的概念(如男人、女人、卡车和狗)也可以使用实体定位方法连接到图像。然而
1)并非所有的概念都可以正确可视化。例如,irreligionist(非宗教主义者)不能指定某种具体醒醒。因此,如何区分可视化概念和非可视化概念成为一个难点
2)如何从一组相关图像中找到一个可视化概念的代表性图像?请注意,可视化概念的图像可能非常多样化。例如,一提到公主,人们往往会想到几种不同的形象,迪士尼公主、历史电影中的古代公主或新闻中的现代公主。因此,我们必须考虑图像的多样性。
Progresses
针对上述挑战,相关研究分为三个任务:可视化概念判断、代表性图像选择和图像多样化。
可视化概念判断
该任务旨在判断概念是否可视化,研究人员发现只有 12.8 %的 Person 子树的同义词集具有公认的可视化性。并且许多其余同义词集没有相应的视觉描述。例如,摇滚明星是可视化的,而求职者是不可视化的。手动注释在构建大规模 MMKG 时明显不实用。
为了自动判断视觉概念,研究人员构建了以下方法,比如:认为抽象名词概念是非可视化的,只收集非抽象名词概念的图像。但是,这些方法都不是很准确。例如,愤怒或快乐可以指定为一个人感到愤怒或快乐的形象。由于图像来自互联网,因此可以使用搜索引擎点击来识别视觉概念。例如,如果谷歌图片点击的数量大于谷歌网络点击的数量,可以表明一个实体可能是可视化的。
此外,可视化的高质量图像的一些特征可以用来识别视觉概念,例如代表性和辨别性。 一些研究人员认为具有代表性图像的前景是相似的,前景易于与背景分离,并且具有较小的类间方差。因此,因此考虑反过来训练分类器来选择其图像集合具有这些特征的概念。
代表性图像选择
该任务本质上旨在根据图像的代表性重新排列图像。图像的代表性是根据基于聚类的方法的结果来评分的,例如 K-means、谱聚类等。聚类内的方差越小,聚类中图像的得分越高。在对图像的代表性得分重新排序后,排在前面的可能是代表性图像。此外,图像也受到规则的约束,以区分不同的簇。例如,一些工作添加了一个新的度量标准来对图像和聚类内的相似度进行排序,即类间距离和类内距离的比率,比率越大,图像的判别力越强。
来自搜索引擎的图像的标题和标签也可以用来评估图像在语义层面的代表性和区分性。标题和标签提供图像没有的语义信息。例如,一张冰岛风景的照片和一张英国风景的照片可能看起来很相似,但文本标签可以帮助我们区分它们的概念差异。一些工作中,标签基于语义特征进行聚类,图像根据标签的语义聚类重新分配到每个聚类中。
多样化图像选择
该任务要求以概念为基础的图像应平衡多样性和相关性。图像也应该在聚类后重新排序,但与代表性图像选择的区别在于,我们想展示尽可能多的集群的结果。 具体来说,在每次选择中,尽量从聚类中选择没有被选择的图像。
这些研究集中在文本图像检索领域,很少有与多模态知识图谱相关的研究。来自互联网的关于性别、种族、肤色和年龄的概念图像的多样性仍然存在许多未解决的偏见,现在这个问题在很大程度上依赖于众包。
Opportunities
抽象概念定位
以前关于概念可视化判断的工作很少考虑抽象概念。但抽象的概念也可以以图像为基础。例如,快乐通常与微笑联系在一起,而愤怒通常与愤怒的脸联系在一起。一些抽象名词具有多样而固定的视觉联想,如自然、人、行为等。例如,“美”的图像与以下词群相关:女人/女孩、水/海滩/海洋、花/玫瑰、天空/云/日落。同样,爱的形象与以下词群相关:婴儿/可爱/新生儿,狗/宠物,心/红/情人节,海滩/海/情侣,天空/云/日落,花/玫瑰。可以看出,一些抽象名词在情感上往往具有一般的、固定的意象,在语义上往往具有辨别性的意象。
动名词概念基础
动名词是一类特殊的名词,可以转化为动词,如singing→sing。通过众包将许多动名词与图片联系起来,例如争吵、摔跤和跳舞。这些涉及人际交往的动词对人的身体角度、注视角度、关节位置和表情等特征较为敏感。
通过实体定位的非可视化概念定位
如果一个概念是非可视化的,但这个概念的实体是可以可视化的,那么这个概念也可以通过它的实体来建立基础。例如,合理选择这样一个概念的接地图像是使用该概念最典型实体的图像。如使用一张爱因斯坦的照片作为物理学家这个概念的基础。这是合理的,因为当我们提到物理学家时,我们大多数人都会想到爱因斯坦。但是,目前还存在许多未解决的问题:(a)一般来说,不同的人对一个概念的思考具有不同的典型实体,因此在概念的基础上要解决这种主观性。一个实体在其概念的约束下是否是一个典型的实体?(b)我们应该选择几个典型实体的图像来表达这个概念。如何总结和选择典型实体来表示概念?(c)我们是否应该从多个实体图像中提取共同的视觉特征?
Relation Grounding
关系定位是从图像数据语料库或互联网中找到可以表示特定关系的图像。输入可以是这个关系的一个或多个三元组,输出应该是这个关系中最具代表性的图像。
Challenges
当我们将三元组作为查询来检索关系的图像时,排名靠前的图像通常与三元组的主题和对象更相关,但与关系本身无关。如何找到能够反映输入三元组语义关系的图像?
Progresses
现有的关系指定研究侧重于空间或动作关系,例如left of、on、ride 和eat。
虽然文本问询可以通过抽象语义表示图(主题、关系、对象)的格式表示为结构化数据,但候选图像也可以结构化为场景图。然后,通过文本-图像匹配或图形匹配,可以将结构化文本和结构化图像进行细粒度匹配,下面将具体展开。
文本图像匹配
在文本-图像匹配任务中,文本和图像通常表示为统一语义嵌入空间中的向量。通过跨模态表示的相似度得分找到与查询最匹配的图像。跨模态表示通常由注意力机制融合,因此全局表示的缺点是缺乏显式细粒度关系的语义。除了基于表示的检索之外,一种更方便的方法是基于标题的检索,如互联网上的搜索引擎。基于标题的检索的缺点是没有使用视觉特征进行匹配。
为了表示对象之间的明确关系,许多研究集中在考虑图像局部结构的图像编码器上。最终的图像表示是全局视觉特征、局部结构特征和文本对齐嵌入的融合。一些工作将所有一阶(实体或概念)、二阶(属性或动作)、三阶(三元组)事实均统一遵循 建模,分别由多层图像编码器的不同分支的输出来表示。 一些研究使用场景图来表示图像中的所有三元组 ,并使用图卷积神经网络来学习视觉关系。最后,每张图像学习到的所有具有关系特征的视觉表示都必须接近。因此,可以通过使用三元组作为查询而不是句子来直接检索匹配的图像。
多模态预训练语言模型是考虑对象(实体或概念)和三元组的图像编码器的新替代方案。对于每个图像-标题对,使用场景图解析器从图像的标题中生成包含对象、属性和关系的场景图,然后将场景图的对象、属性和关系节点随机替换为与对应的词汇表不同的对象、属性或关系来生成大量的硬负样本。 ERNIEViL通过增加三个预训练任务,对象预测、属性预测和关系预测来增强视觉和语言模型的能力。
图匹配
我们期望通过对象和关系的显式匹配而不是统一的跨模态嵌入的隐式匹配来建立关系基础。一种更方便的方法是基于标题的检索,如 Internet 上的搜索引擎,匹配实体的标记与 问询与标题之间的关系。基于标题的检索的缺点是没有使用视觉特征进行匹配。例如,Richpedida 提出了一个非常强的假设,即如果 Wikipedia 描述中的两个实体之间存在预定义的关系(例如 nearBy 和 contains),则两个实体对应的视觉实体之间也存在相同的关系。但实际上,这两个对象更有可能不会同时出现在一张图像中。如果我们将文本查询和候选图像表示为图形,则关系指定任务变成了图形匹配任务,如图 9 所示。可以将图像结构化为图形,其中节点是对象,边是关系。文本问询中的依赖关系可以建模为依赖分析树,它也是一个图。一个简单的解决方案是只匹配两个图中的对象和共现关系而不预测关系类型,即假设如果两个实体之间存在关系,则该关系被认为是匹配的,这也是一个强假设。显然,关系预测模块是必不可少的。 一些研究用GCN分别表示两个场景图,其中对象自己进行更新,关系节点从其邻居的聚合更新。预测时,分别测量两个不同形式的图的相似度:对象节点匹配和关系节点匹配。
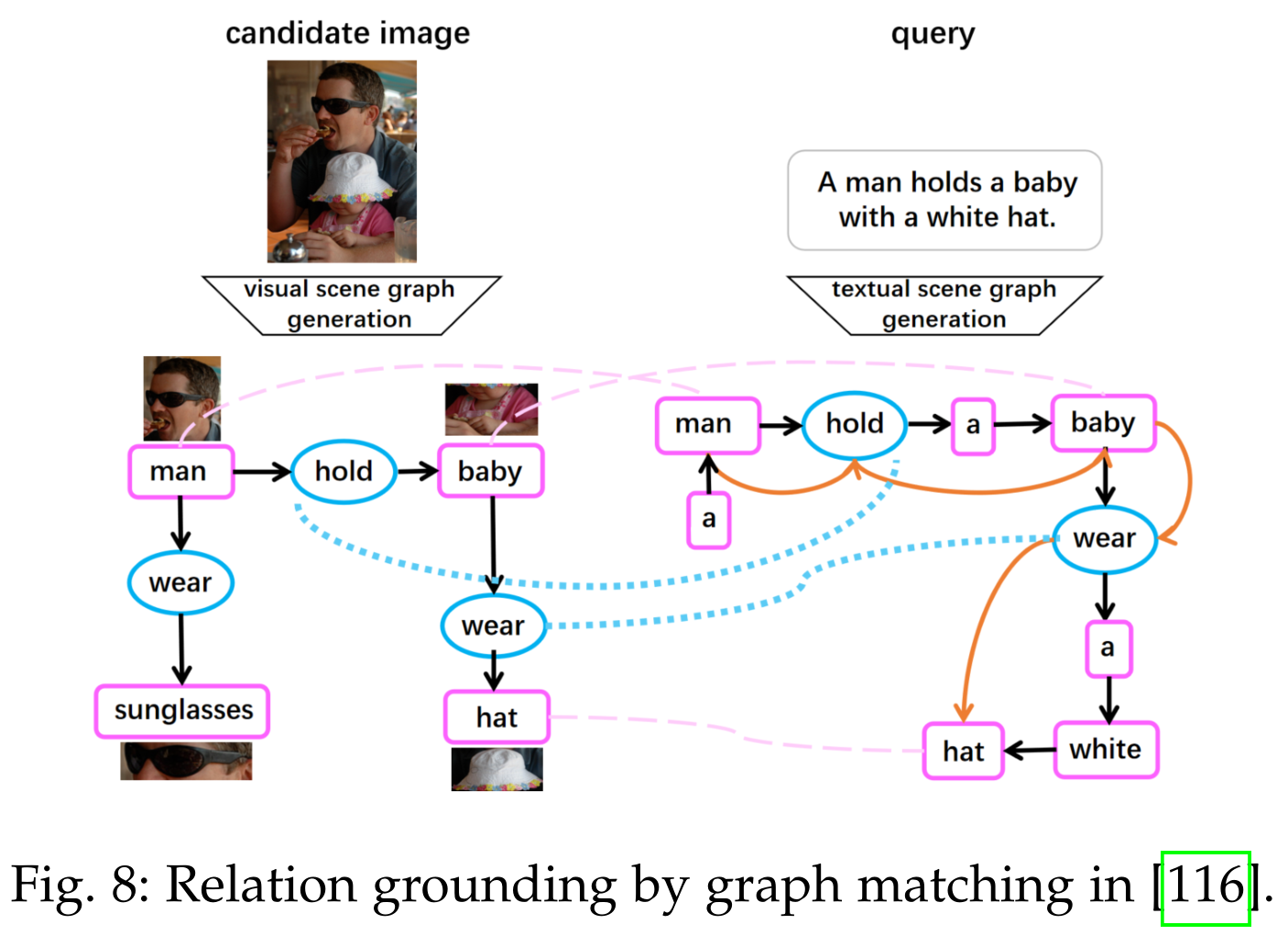
Opportunities
现有研究主要集中在空间关系和动作关系的基础上,这些关系可以在图像中直观地观察到。但是,大多数其他关系例如isA, Occupation, Team and Spouse在图像中可能并不明显。这些关系通常缺乏训练数据,因此很难用上述两种解决方案训练模型来检索图像。
总结/分析
多模态知识图谱综述链接预测部分参考文献
- 134 Translating embeddings for modeling multi-relational data 2013 就是TransE。
- 136 Learning entity and relation embeddings for knowledge graph completion 2015 是TransR。
- 141 Representation learning of knowledge graphs with entity descriptions 2016 具有实体描述的知识图谱表示学习。
- 142 Modeling relation paths for representation learning of knowledge bases 2015 PTransE 对多跳关系的建模。
- 143 Reasoning with neural tensor networks for knowledge base completion 2013 如果两实体名字中有相同的字符串,比如apple pie和apple cake,以往的工作中他们的嵌入是没有什么关系的,这篇以全新的方式(词向量的平均值)来嵌入实体,并且提出了新的神经网络结构ntn。
以上都是单一模态知识图谱的工作,下面的才是多模态的:
138 A multimodal translation-based approach for knowledge graph representation learning 2018 有点像是多模态的transE,主要将多模态信息与图谱结构相结合,三种融合方式,将文本信息与多模态信息拼接,将文本信息映射到多模态信息空间中,将多模态信息映射到文本信息空间中。设计了一个打分(能量)函数。别的没有什么特殊的地方。
144 Image-embodied knowledge representation learning 2016 IKRL是第一个将图像中的视觉信息显式编码为知识表示的尝试。
140 Embedding multimodal relational data for knowledge base completion 2018 提出了多模态知识库嵌入(MKBE),它对这些观察数据使用不同的神经编码器,并将它们与现有的关系模型相结合,以学习实体和多模态数据的嵌入。使用这些学习的嵌入和不同的神经解码器,引入了一种新的多模态插补模型,以从知识库中的信息生成缺失的多模态值,如文本和图像。
23 Answering visual-relational queries in web-extracted knowledge graphs 2017 基于FB15k构建了一个ImageGraph,使用卷积提取视觉特征然后和知识图谱嵌入相结合。给定一个不属于已知kg的图像,该模型可以给出其与另一个给定图像的关系,但我们并不知道他们对应的实体是什么
- 给定一对不可见的图像,我们不知道它们的KG实体,确定潜在实体之间的未知关系。
- 给定一个不可见的图像(我们不知道其底层KG实体)和一个关系类型,确定完成查询的可见图像
- 给定一个不属于KG的全新实体的不可见图像,以及一个我们不知道底层KG实体的不可见图像,确定两个底层实体之间未知的关系。
- 给定一个不属于KG的全新实体的不可见图像和一个已知的KG实体,确定两个实体之间未知的关系。 对于这些查询类型中的每一个,在训练期间都没有观察到底层实体之间的关系。 查询类型(3)和(4)是zero-shot学习的一种形式。因为在训练过程中,新实体与其他实体的关系以及它的图像都没有被观察到。这些考虑说明了可视化查询类型的新颖特性。机器学习模型必须能够学习KG的关系语义,而不是简单地将图像分配给实体的分类器。
24 Mmkg: Multi-modal knowledge graphs 2019 MMKG数据集将三个知识图谱数据集Freebase15k、DBpedia15k和YAGO15k使用sameAs关系连接起来,该文章只学习了sameAs关系,证明了不同模态对同一链接预测任务是互补的。
多模态知识图谱数据集
DBpedia
DBpedia作为近十年来语义网研究的中心领域,其丰富的语义信息也将会成为今后多模态知识图谱的链接端点,其完整的本体结构对于构建多模态知识图谱提供了很大的便利。DBpedia项目是一个社区项目,旨在从维基百科中提取结构化信息,并使其可在网络上访问。DBpedia知识库目前描述了超过260万个实体。对于每个实体,DBpedia定义了一个唯一的全局标识符,可以将其解引用为网络上一个RDF描述的实体。DBpedia提供了30种人类可读的语言版本,与其他资源形成关系。在过去的几年里,越来越多的数据发布者开始建立数据集链接到DBpedia资源,使DBpedia成为一个新的数据web互联中心。目前,围绕DBpedia的互联网数据源网络提供了约47亿条信息,涵盖地理信息、人、公司、电影、音乐、基因、药物、图书、科技出版社等领域。
Wikidata
Wikidata中也存在大量的多模态资源,Wikidata是维基媒体基金会(WMF)联合策划的一个知识图谱,是维基媒体数据管理策略的核心项目。充分利用Wikidata的资源,主要挑战之一是提供可靠并且强大的数据共享查询服务,维基媒体基金会选择使用语义技术。活动的SPARQL端点、常规的RDF转储和链接的数据api是目前Wikidata的核心技术,Wikidata的目标是通过创造维基百科全球管理数据的新方法来克服数据不一致性。Wikidata的主要成就包括:Wikidata提供了一个可由所有人共享的免费协作知识库;Wikidata已经成为维基媒体最活跃的项目之一;越来越多的网站在浏览页面时都从Wikidata获取内容,以增加大数据的可见性和实用性。
IMGpedia
IMGpedia是一个大型的链接数据集,它从Wikimedia Commons数据集中的图像中收集大量的可视化信息。它构建并生成了1500万个视觉内容描述符,图像之间有4.5亿个视觉相似关系,此外,在IMGpedia中单个图像与DBpedia之间还有链接。IMGpedia旨在从维基百科发布的图片中提取相关的视觉信息,从Wikimedia中收集所有术语和所有多模态数据(包括作者、日期、大小等)的图像,并为每张图像生成相应的图像描述符。链接数据很少考虑多模态数据,但多模态数据也是语义网络的重要组成部分。为了探索链接数据和多模态数据的结合,构建了IMGpedia,计算Wikipedia条目中使用的图像描述符,然后将这些图像及其描述与百科知识图谱链接起来。
IMGpedia是一个多模态知识图谱的先例。将语义知识图谱与多模态数据相结合,面对多种任务下的挑战和机遇。IMGpedia使用四种图像描述符进行基准测试,这些描述符的引用和实现是公开的。IMGpedia提供了Wikidata的链接。由于DBpedia中的分类对一些可视化语义查询不方便,所以IMGpedia旨在提供一个更好的语义查询平台。IMGpedia在多模态方向上是一个很好的先例,但也存在一些问题,比如关系类型稀疏,关系数量少,图像分类不清晰等,也是之后需要集中解决的问题。
MMKG
MMKG主要用于联合不同知识图谱中的不同实体和图像执行关系推理,MMKG是一个包含所有实体的数字特征和(链接到)图像的三个知识图谱的集合,以及对知识图谱之间的实体对齐。因此,多关系链接预测和实体匹配社区可以从该资源中受益。MMKG有潜力促进知识图谱的新型多模态学习方法的发展,作者通过大量的实验验证了MMKG在同一链路预测任务中的有效性。
MMKG选择在知识图谱补全文献中广泛使用的数据集FREEBASE-15K (FB15K)作为创建多模态知识图谱的起点。知识图谱三元组是基于N-Triples格式的,这是一种用于编码RDF图的基于行的纯文本格式。MMKG同时也创建了基于DBpedia和YAGO的版本,称为DBpedia-15K(DB15K)和YAGO15K,通过将FB15K中的实体与其他知识图谱中的实体对齐。其中对于基于DBpedia的版本,主要构建了sameAs关系,为了创建DB15K,提取了FB15K和DBpedia实体之间的对齐,通过sameAs关系链接FB15K和DBpedia中的对齐实体;构建关系图谱,来自FB15K的很大比例的实体可以与DBpedia中的实体对齐。但是,为了使这两个知识图谱拥有大致相同数量的实体,并且拥有不能跨知识图谱对齐的实体,在DB15K中包括了额外的实体;构建图像关系,MMKG从三大搜索引擎中获取相应文本实体的图像实体,生成对应的文本-图像关系。但是,它是专门为文本知识图谱的完成而构建的,主要针对小数据集(FB15K, DBPEDIA15K, YAGO15K)。MMKG在将图像分发给相关文本实体时也没有考虑图像的多样性。
还有之前提到的ImageGraph应该也算。
推荐系统
将时序信息引入知识图谱可能效果会更好,因为每个人的兴趣很有可能因为时间而改变,用户链接任务也可以通过引入时序的知识图谱完成?