基于知识图谱的推荐系统综述笔记
简介
- Tittle: A Survey on Knowledge Graph-Based Recommender Systems
- Author: Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Senior Member, IEEE, Xing Xie, Senior Member, IEEE, Hui Xiong, Fellow, IEEE, and Qing He
- Time: 7 October 2020
- Journal: IEEE Transactions on Knowledge and Data Engineering
20年利用知识图谱的推荐系统综述。
基于知识图谱的推荐系统综述
Methods
Embedding-based Method
基于嵌入的方法通过利用kg中的多样事实来丰富item或user的表示,主要分为两个基础模块:图嵌入模块(学习图谱中的实体和关系表示)和推荐模块(使用学习到的特征来估计user对item的倾向)。
分类:the two-stage learning method、the joint learning method 、and the multi-task learning method。
挑战:如何通过正确的知识图谱嵌入方法来获得实体嵌入,如何在推荐模块中结合已学习的实体嵌入。
Two-stage Learning Method 两阶段学习方法
分别训练图嵌入模块和推荐模块,图嵌入模块使用KGE训练之后与user、item的特征一起输入推荐模块进行预测。
优点:容易实现、kge不需要useritem的互动数据,对于大尺度数据集不会增加计算复杂度
缺点:transductive的缺点,训练好之后难以更新,需要重新训练,两模块直接联系不够紧密,不太适合kg外任务(有个解决方法是使用gan或贝叶斯生成模型来初始化实体嵌入)。
Joint Learning Method 联合学习方法
把两模块端到端结合起来一起训练,推荐模块可以指导图嵌入模块的特征学习。
优点:可以端到端地训练,可以利用kg结构来规范推荐系统。
缺点:对于结合不同目的的函数,需要微调(fine-turning)
Multi-task Learning Method 多任务学习方法
多任务学习就像是几个网络共用前多少层,然后对于不同的任务选择不同的分支进行? 使用kg相关的任务来指导推荐任务的训练,动机是因为useritem二部图中的items与kg中关联的实体的结构相似,因此在他们之间传递low-level 特征(有点像是细粒度?比如卷积一次的图还是能看出来原来是什么,卷积多次之后就是high-level feature)对促进推荐系统的提升有帮助。
优点:能帮助避免推荐系统过拟合,提升泛化能力。
缺点:与联合学习方法类似,在一个框架下需要联合不同的任务。
Connection-based Method
基于连接的方法利用图中的连接模式来指导推荐系统。大部分工作利用useritem的kg来挖掘图中实体的关系。
分类:Meta-structure Based Method、and Path-embedding Based methods。
挑战:如何为困难的任务设计合适的元路径,如何建模实体间的连接模式。
Meta-structure Based Method 基于元结构的方法
元结构包括 meta-path 和 meta-graph,利用元结构来计算实体间的相似性,可以作为user和item表示的约束,或者用来从互动历史中的相似user、相似item来预测用户的兴趣。其中一种实现是利用不同元路径的实体的连接相似性作为图规范化来约束user和item的表示,动机是有高度元路径相似度的实体在潜在空间中都比较接近。
优点:容易实现,且大部分都基于矩阵分解技术(MF),使得模型复杂度低。
缺点:元路径或元图的选择需要相应领域的知识,且这些元结构在不同的数据集中差距很大。在某些特殊场景,该方法并不合适,例如新闻推荐任务中,一个新闻的实体可能属于不同的领域,使得很难设计元路径。连接模式没有明确地建模,因此这个方法缺乏一定的表示能力(FMG通过用元图代替元路径,捕捉更丰富的语义来解决这个问题)。
Path-embedding Based methods 基于路径嵌入的方法
基于元结构的方法中有个问题就是连接模式没有明确地建模,这使得很难学到useritem对和连接模式之间的相互作用。基于路径嵌入的方法就是来明确学习连接模式的嵌入。一些工作学习useritem知识图谱中的useritem对的连接、或item知识图谱中的itemitem对的连接的路径的明确嵌入来直接对useritem关系或itemitem关系建模。
优点:能够考虑目标用户、候选item和连接模式之间的相互作用。大部分模型能不借助预定义的元结构的帮助,自动地通过计算合格的路径并选择主要的那些来挖掘连接模式。因此可以能捕捉有表达力的连接模式。
缺点:如果图中的关系十分复杂,可能的路径数会相当大。实际中几乎不可能利用大规模知识图谱中每个实体对的所有路径,不然会妨碍模型的性能。
Propagation-based Method
High-order relations contain spatial relations (e.g., “behind”, “below”, “left”) and semantic relations (e.g., “playing”, “wearing”, “holding”). Then these relations are combined with visual features to enrich the representations of images.
基于嵌入的方法利用知识图谱中的语义关系来丰富用户与物品表示或规范化推荐,但很难捕捉实体间的高阶关系(high-order relations)。 基于连接的方法将复杂的useritem连接模式分解为线性路径,不可避免地会丢失信息。 基于传播的方法结合实体关系表示和高阶连接模式来创造一个更加人性化的推荐系统。基于传播的方法是基于表征传播(embedding propagation)的思想。这些方法(GNN)通过聚合多跳邻居节点完善了实体嵌入,然后再进行推荐。
基于传播的方法一般都很消耗计算资源,为了提升效率,提出了更快的图卷积操作,在每层中通常使用邻居采样。然而随机采样会不可避免地损失信息,无法完整地explore图中的知识。
分类:Refinement of User Representation、Refinement of Item Representation、and Refinement of both User and Item Representation。
挑战:如何给不同的邻居分配合适的权重,如何在不同关系的边上传播信息,如何提升模型的泛化能力。
Refinement of User Representation 丰富用户表示
基于用户的互动历史来丰富用户表示,这些工作构建多种关系连接互动items和候选items的item KG。动机是用户可以通过他们互动过的items和其多跳邻居来聚合为一个整体。
优点:在这个方法中item KG的边的权重是明确的,因此可以选择连接候选item与交互过的item的主要路径(salient path)来作为推荐结果的解释。
缺点:尽管利用了实体嵌入和高阶连接信息,在传播过程中只有用户表示得到了更新。
Refinement of Item Representation 丰富物品表示
在item KG中,通过聚合候选物品的多跳邻居来学习其高阶表示。在向内的传播过程中,采用图注意力机制,其中不同邻居的权重是根据用户与关系特定的。动机是用户对不同的关系会有不同的倾向,这会引导知识图谱中的信息流动。
优缺点与丰富用户表示类似。
Refinement of both User and Item Representation 丰富用户与物品表示
在useritem KG中的传播机制,user、item和他们相关联的实体都在一张图中连接起来,useritem对之间的交互可以看作关系的一种。用户与物品嵌入可以通过他们相关的邻居节点上的传播过程来进行增强。
和我想的useritementity的知识图谱很像,使用这种方法来获得user和item的嵌入,然后进行推荐预测。但本质上还是基于嵌入的链接预测?没法处理新的item和新的user,不然要重新嵌入,而且也会遇到冷启动问题?
优点:权重也是user-specific的,所以也有一定的可解释性。特别是user也作为node,所以解释更直觉,高阶连接模式被充分利用。
缺点(downside):图中更多的关系会带来不相关的实体,这会误导聚合过程中的用户倾向(为了解决,AKGE在子图中学习useritem对的加强表示)。
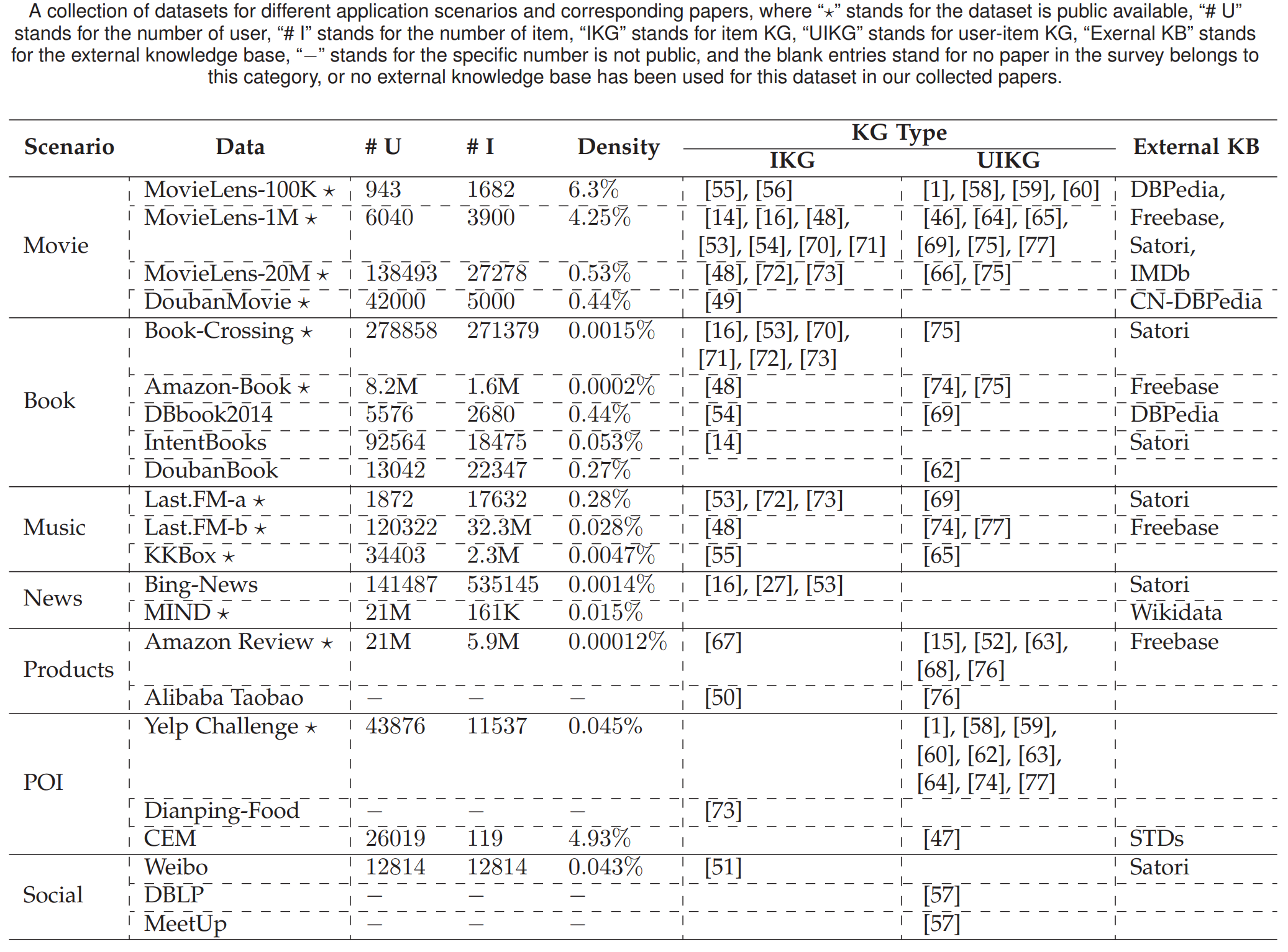
Datasets
See Table.1 .
Future Directions
动态推荐
GNN或GCN架构的KG-based推荐系统效果很好但是很耗时,因此可以被视作静态推荐。但在某些场景中,用户的兴趣会被社会事件或是朋友快速影响,这种情况下静态推荐无法理解实时的兴趣。可以利用动态图网络,来捕捉动态倾向。
多任务学习
KG-based推荐系统可以自然地视为图中的链接预测,所以考虑知识图谱的特性可能可以提升基于知识图谱的推荐性能。比如,kg中可能存在缺失事实,导致缺失关系或缺失实体,然而用户的倾向可能会因为这些事实的缺失而被忽略,这可能是推荐结果的决定性因素。Papers [54], [71] 显示训练知识图谱补全后的推荐系统会有更好的结果。其他工作利用多任务学习,通过用kge任务[53]和item关系规范任务[55]来训练推荐模块。充分利用其他kg任务如实体分类与分解来将知识转移从而提升推荐效果会很有趣。
跨领域推荐
跨领域的交互数据是不均衡的,比如亚马逊平台的书的集合是大于别的领域的。通过迁移学习技术,源领域的交互数据可以被目标领域所利用,从而更好地推荐。Zhang et al. [110]提出了基于矩阵的方法来跨领域推荐,Zhao et al. [111]提出了PPGN,将不同领域的user和products放在一种图中,然后利用useritem交互图来跨领域推荐。尽管PPGN效果很好,但useritem图只包含了交互信息,没有考虑其他的关系。合并不同类型的useritem数据来进行跨领域推荐的前景不错。
知识增强的语言表示
将额外的知识集成到语言表示模型中来提升各种nlp任务,这样可以人为增强知识表示和文本表示。在新闻推荐系统或是其他基于文本的推荐任务中采用知识增强的文本表示很有前景,能有更好的表示学习,促进更准确的推荐。